Bigtable
Reading notes
Motivation
- Lots of (semi) structure data: URLs, Geo
- Scale is large
- want asynchronous processes to be continuously updating different pieces of data
Big table

Building Blocks
- GFS: stores persistent data
- SSTable (file format): is used internally to store Bigtable data.
- (key, value) (both are arbitrary byte strings)
- each SSTable contains a sequence of blocks (typically each block is 64KB in size, but this is configurable)
- A block index (stored at the end of the SSTable) is used to locate blocks; the index is loaded into memory when the SSTable is opened.
- Scheduler: schedules jobs onto machines
- Lock service (Chubby):
- Lock service: distributed lock manager
- master election, location bootstrapping
- MapReduce
Data model
- (row:string, column:string, time:int64) → string
Rows
- Arbitrary string
- Access to data in a row is atomic
- Ordered lexicographically
Column
- Tow-level name structure:
- family: qualifier
- Column Family is the unit of access control
Timestamps
- Store different versions of data in a cell
- Lookup options
- Return most recent K values
- Return all values

Implementation
- Single-master distributed system
- The Bigtable implementation has three major components:
- a library that is linked into every client
- one master server
- is responsible for assigning tablets to tablet servers
- detecting the addition and expiration of tablet servers
- balancing tablet-server load
- garbage collection of files in GFS.
- In addition, it handles schema changes such as table and column family creations.
- many tablet servers (can be dynamically added or removed)
- clients communicate directly with tablet servers for reads and write.
Tablet location
Given a row, how do clients find the location of the tablet whose row range covers the target row?

METADATA: Key: table id + end row, Data: location
Aggressive Caching and Prefetching at Client side
Chubby file
- The first level is a file stored in Chubby that contains the location of the root tablet.
- Root tablet
- contains the location of all tablets in a special METADATA table.
- first tablet in the METADATA table
- never split to ensure 3-level hierarchy
Tablet Assignment
- Each tablet is assigned to one tablet server at a time
- uses Chubby to keep track of tablet servers
- When a tablet server starts, it creates, and acquires an exclusive lock on, a uniquely-named file in a specific Chubby directory
- Chubby
- Tablet server registers itself by getting a lock in a specific directory chubby
- Chubby gives “lease” on lock, must be renewed periodically
- Server loses lock if it gets disconnected
- Master monitors this directory to find which servers exist/are alive
- If server not contactable/has lost lock, master grabs lock and reassigns tablets
- GFS replicates data. Prefer to start tablet server on same machine that the data is already at
- Tablet server registers itself by getting a lock in a specific directory chubby
Tablet Serving
memtable: the recently committed ones are stored in memory in a sorted buffer.

Compactions
minor compaction
- When the memtable size reaches a threshold, the memtable is frozen, a new memtable is created, and the frozen memtable is converted to an SSTable and written to GFS
- two goals:
- it shrinks the memory usage of the tablet server
- it reduces the amount of data that has to be read from the commit log during recovery if this server dies.
merging compaction
- A merging compaction reads the contents of a few SSTables and the memtable, and writes out a new SSTable.
major compaction
- A merging compaction that rewrites all SSTables into exactly one SSTable
Refinements
- Locality groups
- Compression
- Caching for read performance
- two level
- Scan Cache: cache key-value pairs
- Block Cache: cache SSTables blocks (better for sequential reads)
- two level
- Bloom filters
- A Bloom filter allows us to ask whether an SSTable might contain any data for a specified row/column pair.
- Commit-log implementation
- per tablet server
- co-mingling mutations for different tablets
- high performance, but complicates recovery.
- Speeding up tablet recovery
- the source tablet server first does a minor compaction on that tablet
- the tablet server stops serving the tablet
- minor compaction to eliminate any remaining uncompacted state in the tablet server’s log
- the tablet can be loaded on another tablet server
- Exploiting immutability
- (SSTables is immutable)
- Each tablet’s SSTables are registered in the METADATA table.
- The master removes obsolete SSTables as a mark-and-sweep garbage collection over the set of SSTables, where the METADATA table contains the set of roots.
- the immutability of SSTables enables us to split tablets quickly (let the child tablets share the SSTables of the parent tablet)
Class notes
A NoSQL (originally referring to "non SQL" or "non relational")[1] database provides a mechanism for storage and retrieval of data which is modeled in means other than the tabular relations used in relational databases.
APIs
- Metadata operations
- Create/delete tables, column families, change metadata
- Writes
- Set(): write cells in a row
- DeleteCells(): delete cells in a row
- DeleteRow(): delete all cells in a row
- Reads
- Scanner: read arbitrary cells in a bigtable
- Each row read is atomic
- Can restrict returned rows to a particular range
- Can ask for just data from 1 row, all rows, etc.
- Can ask for all columns, just certain column families, or specific columns
- Scanner: read arbitrary cells in a bigtable
Typical Cluster
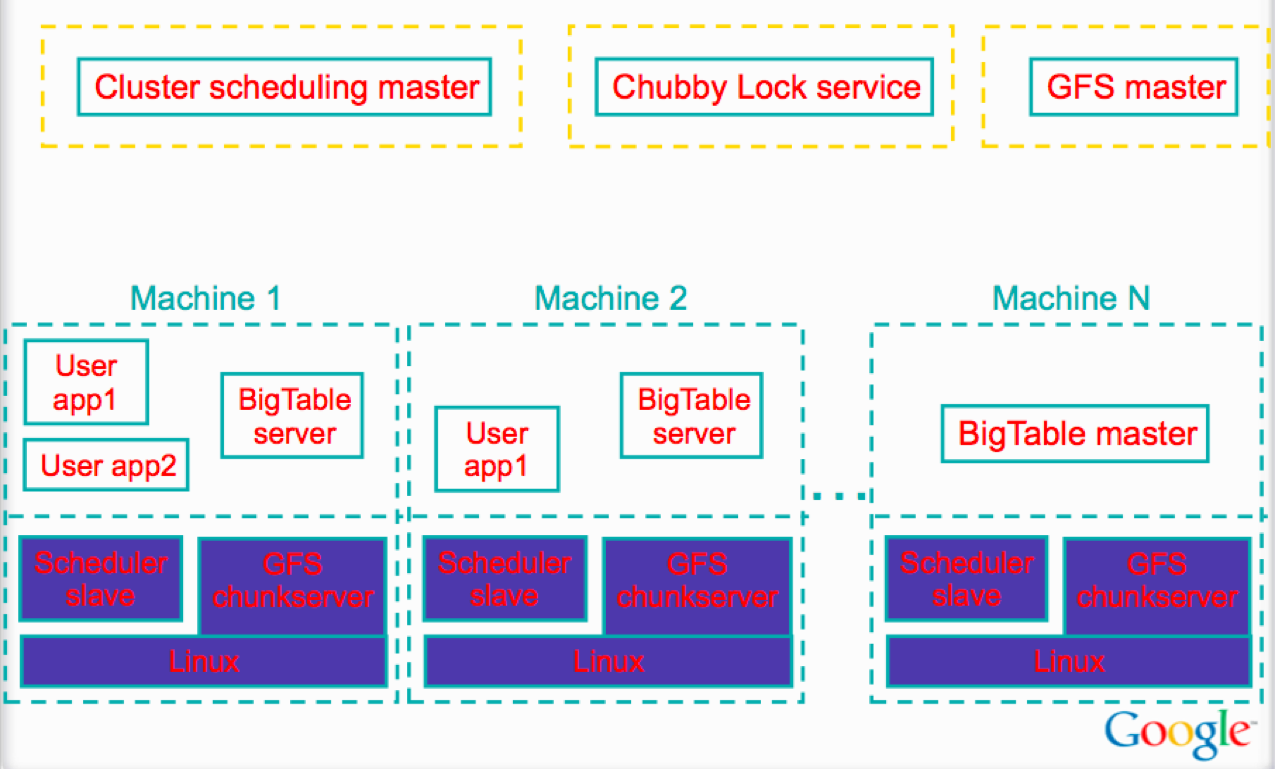
Chubby
- {lock/file/name} service
- Coarse-grained locks
- Each clients has a session with Chubby.
- The session expires if it is unable to renew its session lease within the lease expiration time.
- 5 replicas, need a majority vote to be active
Questions
What is the responsibility of the master node?
- Assigning tablets to tablet servers
- load balancing across tablet servers
- detecting tablet server status